|
I am a fourth-year Ph.D. student at the Gaoling School of Artificial Intelligence, Renmin University of China, supervised by Prof. Wayne Xin Zhao. I have a broad interest in Multimodal Large Language Models (MLLMs), especially VL post-training and long video understanding. Now I'm also interested in Multimodal Agent (e.g., Omni Search Agent). Email / Github / Google Scholar / Twitter I will graduate at 2027 Fall. Feel free to contact me via email if your are recruting! |

|
|
My current research focuses on Multimodal Large Language Models (MLLMs). I am particularly interested in visual instruction tuning, long video understanding, and complex visual reasoning. Representative works include Virgo (reproducing o1-like MLLM) and POPE (evaluating object hallucination in LVLMs). |
|
(* denotes equal contribution.) |

|
Yifan Du*, Kun Zhou*, Yingqian Min, Yue Ling, Wayne Xin Zhao, Youbin Wu CVPR 2026 Paper / Code |

|
Dong Guo, Faming Wu, Feida Zhu, Fuxing Leng, Guang Shi, Haobin Chen, Haoqi Fan, ...Yifan Du, ... arXiv 2025 Paper / Code |
|
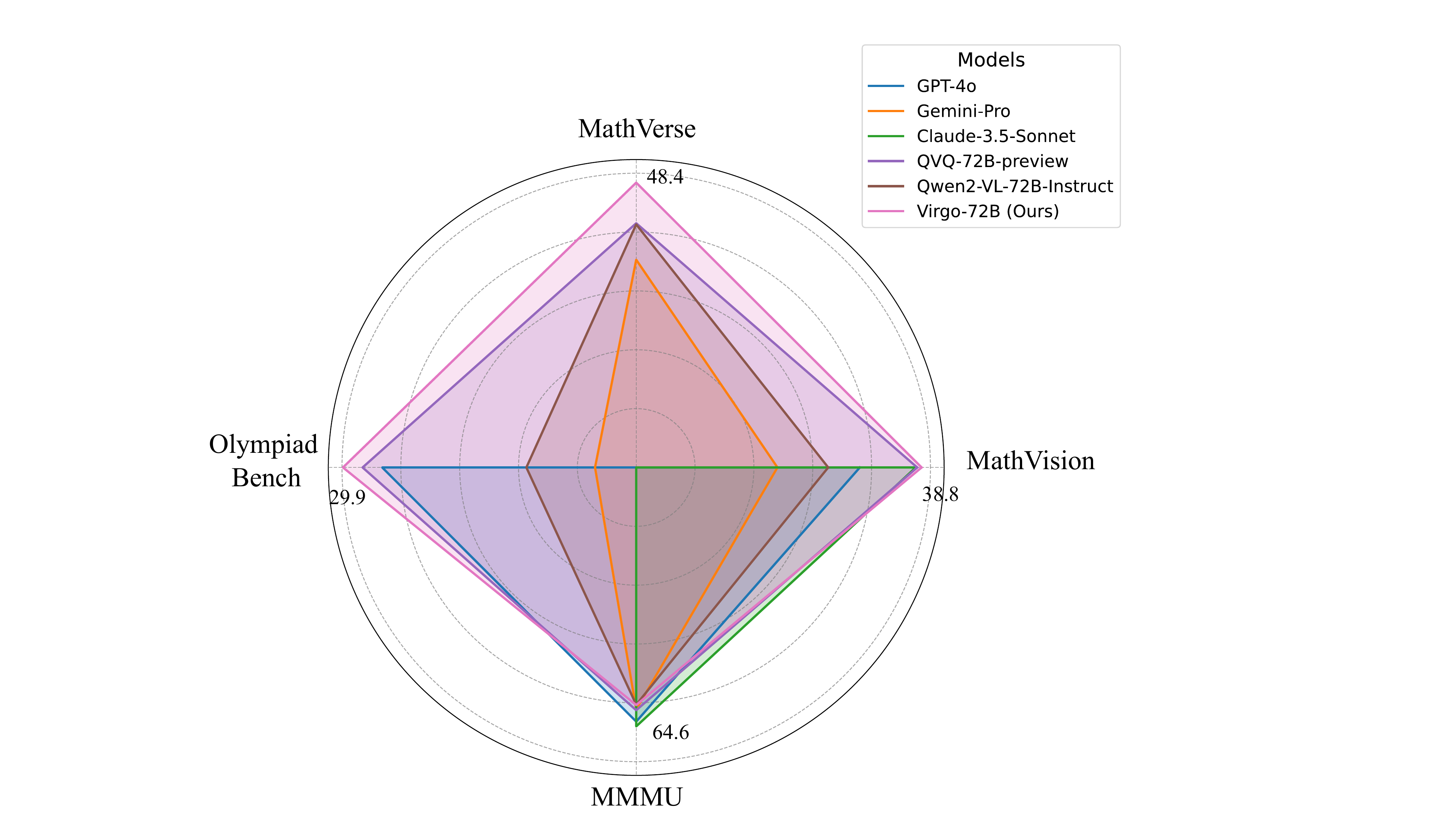
Yifan Du*, Zikang Liu*, Yifan Li*, Wayne Xin Zhao, Yuqi Huo, Bingning Wang, Weipeng Chen, Zheng Liu, Zhongyuan Wang, Ji-Rong Wen arXiv 2025 Paper / Code |
|
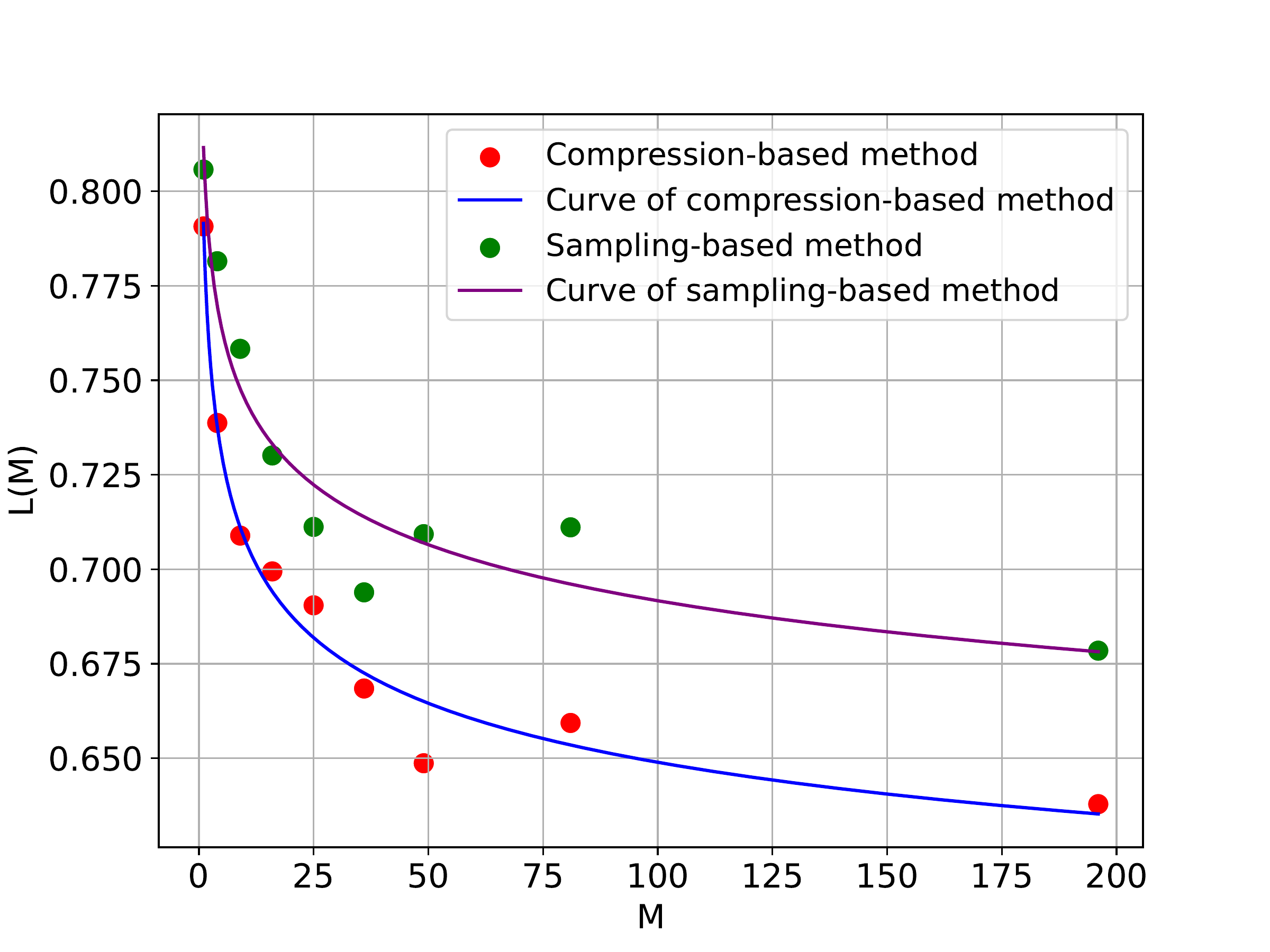
Yifan Du*, Yuqi Huo*, Kun Zhou*, Zijia Zhao, Haoyu Lu, Han Huang, Wayne Xin Zhao, Bingning Wang, Weipeng Chen, Ji-Rong Wen ICLR 2025 Paper / Code |

|
Yifan Du*, Kun Zhou*, Yuqi Huo, Yifan Li, Wayne Xin Zhao, Haoyu Lu, Zijia Zhao, Bingning Wang, Weipeng Chen, Ji-Rong Wen arXiv 2024 Paper / Code |
|
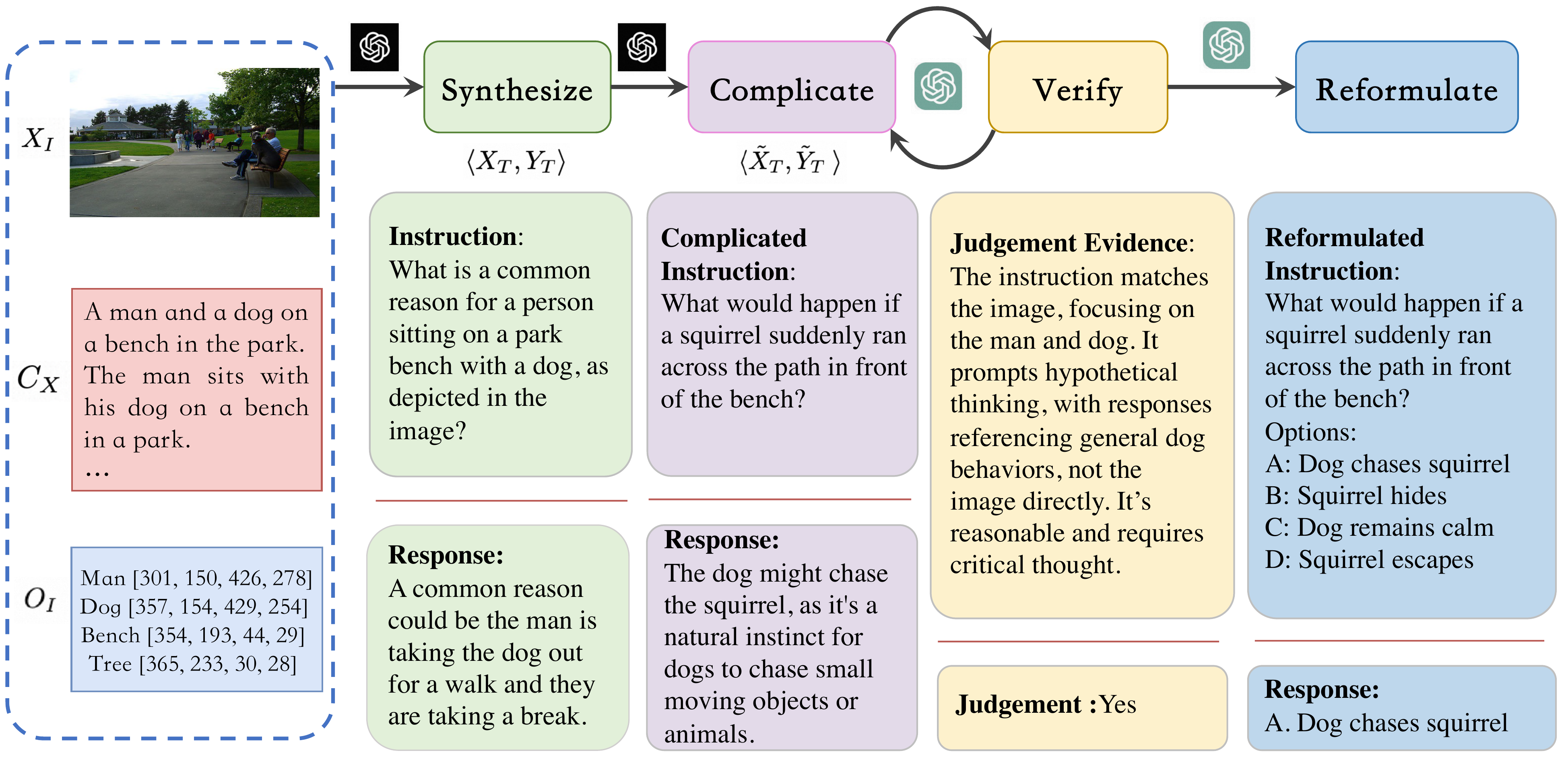
Yifan Du*, Hangyu Guo*, Kun Zhou*, Wayne Xin Zhao, Jinpeng Wang, Chuyuan Wang, Mingchen Cai, Ruihua Song, Ji-Rong Wen COLING 2025 Paper / Code |

|
Yifan Li*, Yifan Du*, Kun Zhou*, Jinpeng Wang, Wayne Xin Zhao, Ji-Rong Wen EMNLP 2023 Paper / Code |

|
Wayne Xin Zhao, Kun Zhou*, Junyi Li*, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, Yifan Du, Chen Yang, Yushuo Chen, Zhipeng Chen, Jinhao Jiang, Ruiyang Ren, Yifan Li, Xinyu Tang, Zikang Liu, Peiyu Liu, Jian-Yun Nie, Ji-Rong Wen arXiv 2023 Paper / Code |
|
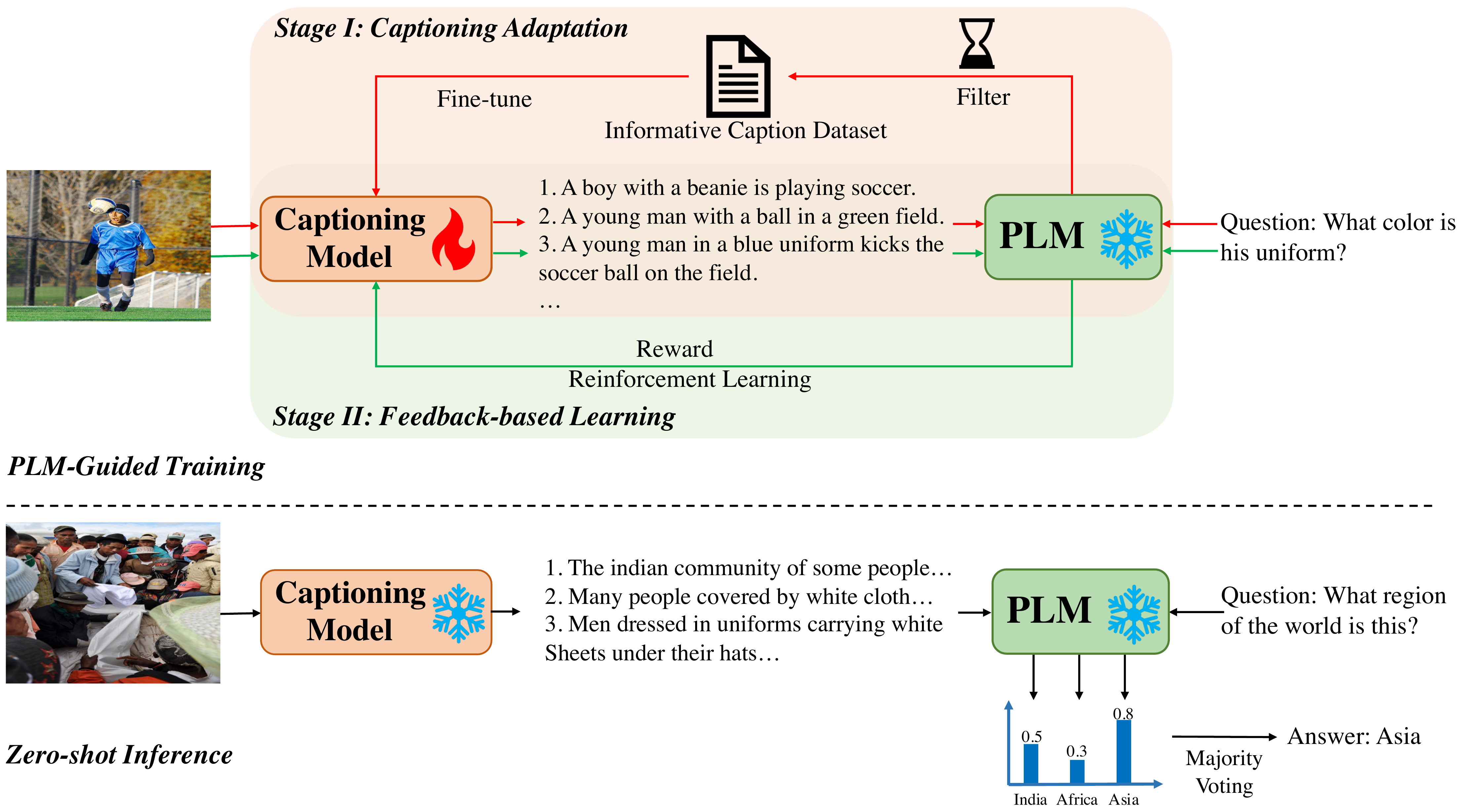
Yifan Du, Junyi Li, Tianyi Tang, Wayne Xin Zhao, Ji-Rong Wen ACL 2023 Paper / Code |

|
Tianyi Tang, Yushuo Chen, Yifan Du, Junyi Li, Wayne Xin Zhao, Ji-Rong Wen ACL 2023 Paper / Code |

|
Yifan Du*, Zikang Liu*, Junyi Li, Wayne Xin Zhao IJCAI 2022 Paper |
|
|
|
|
Ph.D. student in Artificial Intelligence (2022 - 2027 Expected) Advisor: Prof. Wayne Xin Zhao |
|
|
B.Sc. in Statistics (2018 - 2022) |
|
|
|
|
VLM Post-training Intern (Feb. 2025 - Present) |
|
|
MLLM Research Intern (Apr. 2024 - Jan. 2025) |
|
|
Research Intern (Apr. 2023 - Mar. 2024) |
|
|
|
Thanks Jon Barron for this amazing template.
|